Special Session and Competition on LSGO on WCCI'2020
Table of Contents
Introduction
In the past two decades, many evolutionary algorithms have been developed and successfully applied for solving a wide range of optimization problems. Although these techniques have shown excellent search capabilities when applied to small or medium sized problems, they still encounter serious challenges when applied to large scale problems, i.e., problems with several hundreds to thousands of variables. This is due to the Curse of dimensionality, as the size of the solution space of the problem grows exponentially with the increasing number of decision variables, there is an urgent need to develop more effective and efficient search strategies to better explore this vast solution space with limited computational budgets. In recent years, research on scaling up EAs to large-scale problems has attracted significant attention, including both theoretical and practical studies. Existing work on tackling the scalability issue is getting more and more attention in the last few years.
In recent years, research on scaling up EAs to large-scale problems has attracted significant attention, including both theoretical and practical studies. Existing work on tackling the scalability issue is getting more and more attention in the last few years.
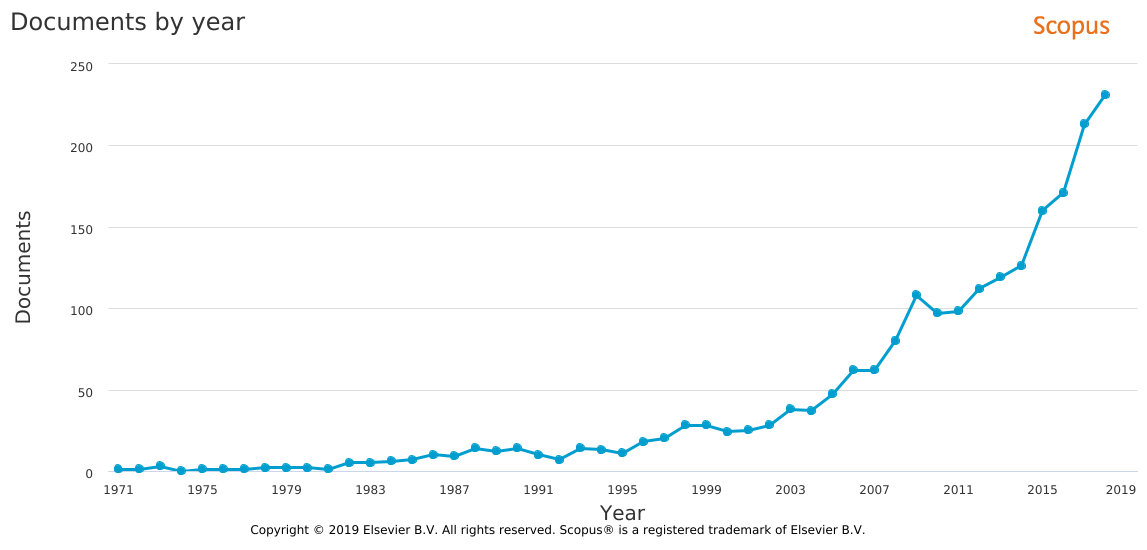
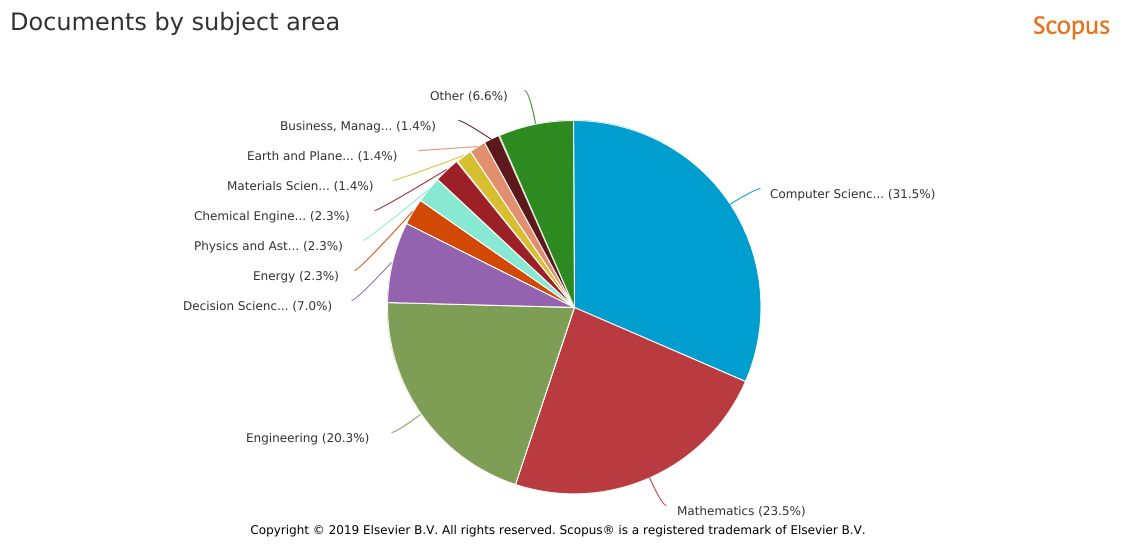
This special session is devoted to highlight the recent advances in EAs for handling large-scale global optimization (LSGO) problems, involving single objective or multiple objectives, unconstrained or constrained, static or dynamic, binary/discrete or real, or mixed decision variables. More specifically, we encourage interested researchers to submit their original and unpublished work on:
- Theoretical and experimental analysis on the scalability of EAs;
- Novel approaches and algorithms for scaling up EAs to large-scale
optimization problems; this includes but not limited to the follow:
- ◦ Exploiting problem structure by means of variable interaction analysis and problem decomposition.
- ◦ Hybridization and memetic algorithms.
- ◦ Designing algorithm-specific sampling and variation operators.
- ◦ Approximation methods and surrogate modeling.
- ◦ Parallel EAs and distributed computing models.
- ◦ Using machine learning and data mining to boost the performance of EAs.
- ◦ Hybridization between EAs with traditional mathematical approaches.
- Problem areas such as: large-scale multi-objective problem, problems with overlapping components, resource allocation and the imbalance problem, constrained handling in high-dimensional spaces.
- Applications of EAs to real-world large-scale optimization problems; e.g., optimization problems in machine learning, healthcare and scheduling etc.
- Novel test suites that help researches to understand large-scale optimization problems characteristics.
Paper Submission
Manuscripts should be prepared according to the standard format and page limit of regular papers specified for WCCI’2020. Instructions on the preparation of the manuscripts can be obtained at the WCCI’2020 website: https://wcci2020.org/calls/#call-for-papers. Special session papers will be treated in the same way as regular papers and will be included in the conference proceedings. Submissions should be done by using the following link: https://wcci2020.org/calls/#call-for-papers.
Deadline: 15 January 2020
Participate into Competition
You could participate into the competition without submit to the Special Session. In that case, you had to submit us information about the paper (algorithm name, authors, citation if it was published), and the Excel file with all the results results_all.xls to tflsgo@gmail.com). This Excel file contains not only the required milestones (1.2e5, 6e5, 3e6) but also additional values to analyze the performance of the different algorithms.
Deadline: 15 January, 2020.
Benchmark Competition
Furthermore, a companion competition on Large Scale Global Optimization (LSGO) will also be organized together with the special session. The competition allows participants to run their own algorithms on 15 benchmark functions, each of them of 1000 dimensions. Detailed information about these benchmark functions is provided in the following technical report:
The aim of this competition is to provide a common platform that encourages fair and easy comparisons across different LSGO algorithms. Researchers are welcome to apply any kind of evolutionary computation technique to the test suite. The technique and the results can be reported in a paper for the special session (i.e., submitted via the online submission system of CEC’2019). However, it is not needed to submit the proposal to the CEC’2019 Special Session for participating into the LSGO competition.
The authors must provide their results as shown in the aforementioned technical report (Table 2). In particular, this table must contain the statistical information of their results at different checkpoints of the execution: 1.2E5, 6.0E5, and 3E6 fitness evaluations, being 3E6 the maximum number of evaluations.
In order to make it easier to obtain the results in the requested format, the original source code of the benchmark has been modified to automate this task. This modified code will output the requested information in an external file at the desired checkpoints. Right now, C++, Matlab and Python versions of the benchmark support this feature. Additionally, several tools are provided to create an Excel file with the results as recorded by the modified code and the latex table (Table 2 of the technical report) to allow its easy inclusion in the paper. However, the use of this version of the code is optional: the original code can still be used provided that the requested information is gathered by the algorithm.
Original Code
The original code (C++, Java and Matlab implementations) is available in the following link: lsgo_2013_benchmarks_original.zip
For Python users, Prof. Molina is maintaining a Python version of the test
suite, which can be found in the following website:
https://pypi.python.org/pypi/cec2013lsgo
and can installed by simply doing: pip install cec2013lsgo==0.1.
New code
The source code (modified for the C++ and Matlab implementations) is
available in the following link:
lsgo_2013_benchmarks_improved.zip.
The source code for Python users can installed by simply doing: pip install
cec2013lsgo==0.2 or pip install cec2013lsgo.
Also, the source code of the benchmark can be obtained from their repository.
As stated before, these modified versions save all the results into separate files named results_num.csv (for each function num and at the different checkpoints). However, if multiple runs for the same function are conducted concurrently, the user can change the default filename for the output file (please, check the examples for each version of the source code).
Additionally, if all the runs are done within the same program, in order to allow to store these values for each of the runs you have to inform the code when a new run is starting:
-
In the C++ implementation, you should use the method nextRun() among different runs (and for first time).
-
In the Matlab implementation, you need to set the global variable initial_flag to 0 just before each run.
Finally, the zip file also includes a small utility in Python, extract_data.py that receives as a parameter the directory where the .csv files are stored and generates (it requires pandas):
-
results_all.xls: An Excel file with all the results (we encourage the participants to submit the results in this format by email to the organizers, tflsgo@gmail.com). This Excel file contains not only the required milestones (1.2e5, 6e5, 3e6) but also additional values to analyze the performance of the different algorithms.
-
results.tex: A Latex file with all the required values as in Table 2 of the technical report to be included in the paper.
Automatic comparisons
In order to help researchers to compare their proposals with previous winners, we have developped a website https://tacolab.org. This website allows researchers to compare the data of their proposal (provided in an Excel file) with those of previous algorithms. Several reports, both as tables and figures, can be automatically generated by this tool (and exported to be included in the manuscript). In particular, the report LSGO Competition plots allows you to compare your results according to the criteria used in the special session.
Previous winners (useful as reference algorithms) are:
- CC-RDG3: doi:10.1109/CEC.2019.8790204: Winner in 2019.
- DGSC doi:10.1109/CEC.2019.8790056: Runner-up in 2019.
- SHADE-ILS doi:10.1109/CEC.2018.8477755: Winner in 2018.
- MLSHADE-SPA doi:10.1007/s40747-018-0086-8: Runner-up in 2018.
- MOS doi:10.1007/s12293-013-0120-8: Winner in previous years 2013-2018.
You can check results of previous competition.
Organizers



University Politécnica de Madrid, Spain.

University of Granada, Spain.